|
Viatscheslav Iatsko, Serghei Shilov, Timur Vishniakov (Abakan/Russia) Semi-automatic Text Summarization and Foreign Language TeachingSemi-automatic Text Summarization and Foreign Language Teaching 1 IntroductionText summarization plays crucial role in the development of effective and efficient information retrieval (IR) systems. The issue of effectiveness relates to the problem of finding relevant information in the huge volumes becoming available on-line (see The Center for Intelligent Information Retrievel, 2000). Even very effective retrieval techniques can find large amounts of potentially interesting information, and it is important for a system to provide additional tools such as extraction and summarization. Progress in text summarization and extraction will not only enable the development of better retrieval systems, but will also support the access and analysis of text-based information in a number of novel ways helping to create discrete as well as continual access systems. Integrated into existing automatic information retrieval systems they can be effectively used in the Internet search engines, providing users with summaries of documents thus enabling them to better identify relevant documents. Continual systems with access to newspaper corpora can also provide user with event tracking and topic shift opportunities (see Iatsko). PhiN 34/2005: 49 Text summarization has also been widely used in foreign language teaching (FLT) (see Veize 1985), since it involves such skills as memorizing and correctly using in speech a number of lexical units, transforming syntactic structures and defining connections between sentences. Until recently there have been essential differences between text summarization in FLT and in IR: while FLT summarization techniques have been applied manually, within the scope of IR the emphasis has been traditionally made on automatic summarization. Recent developments in computer technologies have made it possible to create double-purpose summarization techniques, i.e. one and the same technique, when semi-automatic can be effectively used in FLT, when fully automatic can serve purposes of IR. Such summarization technique described here is symmetric summarization. This paper is aimed at: 1) outlining main criteria for classification of automatic summarization systems, 2) describing methodology of symmetric summarization and its possible uses in IR and FLT, 3) describing architecture and functioning of PASS (partially automatic symmetric summarization) system that was developed to be used in teaching English as a foreign language (TEFL). 2 Classification of automatic text summarization systems2.1 Criteria for classification of ATSSSince its beginnings, main function of text summarization has been to help the user to find information that he needed by distilling the most important information from a primary source and producing its abridged version. Thus text summarization can be considered an intermediary between the user and information contained in various documents. Contemporary automatic text summarization systems (ATSS) can be classified according to 1) their relation to user needs, 2) their relation to text corpora that are summarized, 3) functions of summaries they produce, 4) summarization methodologies. An ATSS can be user-focused if it produces summaries relying on a specification a user information need (for example in response to a user's query), or it can be generic if it produces summaries aimed at broad audience (an example is abstract journals). An ATSS can be discrete if it produces a summary that reflects the contents of a separate primary source, or it can be continual if it produces a summary that reflects the contents of a number of primary sources (multiple documents summary). A subtype of continual ATSS is an event-tracking system, in which summaries are arranged in chronological order to reflect the development of one and the same event. An ATSS can be domain specific if it summarizes texts belonging to a specific subject field, or it can be domain independent, allowing to summarize documents in any field without including any specific domain knowledge. An ATSS can be abstracting if it produces coherent summaries that resemble manually created summaries (abstracts), or it can be extracting if the resulting summary (extract) contains incoherent fragments of primary source. An ATSS can be indicative if it generates indicative summaries, or it can be informative, if the resulting summaries are informative. PhiN 34/2005: 50 Mani and Maybury (1999) suggested that ATSS, depending on methodologies they employ, should be classified into surface-level, entity-level, and discourse-level. Surface level ATSS process primary sources basing on shallow features, such as presence of statistically salient terms, location of terms in text, cue words. Entity-level ATSS are based on modeling semantic, syntactic, and logical relations between text entities. Discourse-level ATSS are based on modeling the global structure of the text. Table 1 presents characteristics of contemporary ATSS. 
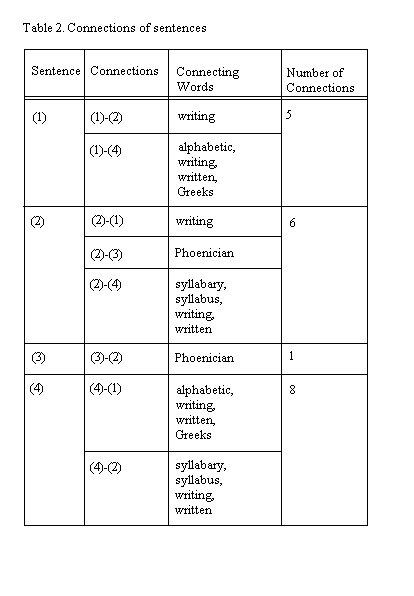
Contemporary ATSS are often of a hybrid character, i.e. they can combine characteristics distinguished by one and the same criterion. For example, FociSum, an ATSS developed at Columbia University (see Kan & McKeown 1999), can be described as a generic, domain independent, discrete system that generates coherent informative summaries and employs entity level as well as surface level methodologies. At surface level FociSum's preprocessing module makes a statistic analysis to define most salient terms; at entity level its main module, basing on question-answering templates, specifies semantic relations between the terms and generates a summary. PhiN 34/2005: 51 Another example of a hybrid ATSS is a summarizer developed by Tomek Strzalkowski et al. (1999). The summarizer can work in two modes: generic and user-focused. In generic mode it summarizes main points of the original document; in user-focused mode it takes a user-supplied statement of interest (topic) and derives a summary related to this topic. 2.2 Semi-automatic summarization systemsWithin the scope of computer science work on text summarization has been naturally focused upon fully automatic systems that serve the purposes of information retrieval. Semi-automatic text summarization systems (SATSS) can be successfully applied in some other subject fields, for example in foreign language teaching. A semi-automatic text summarization system is a system, in which at least one of the summarization procedures is fulfilled manually by the user. For example, surface-level text summarization systems are supposed to employ the following procedures 1) making up a dictionary that serves as a data-base. The dictionary can be created manually by an expert in a subject field or it can be created dynamically by an ATSS. The dictionary can pertain to a certain subject field in domain dependent ATSS, or may include lexical units that are not associated with a subject field in domain independent ATSS; 2) dividing the input text into linguistic units, usually sentences; 3) scanning the input text to find sentences containing dictionary units; 4) ranking sentences according to some criteria. Most surface-level ATSS use statistical criteria, i.e. frequency of occurrence of dictionary units. Sentences, in which dictionary units occur or co-occur more often, are assigned higher ranks; 5) defining summary size, i.e. number of sentences in the summary; 6) extracting from the primary source sentences with highest ranks. The number of sentences corresponds to the summary size; 7) making up a summary. The first two procedures are realized by a preprocessing module of an ATSS, and the next five – by the summarization module. A semi-automatic text summarization system is a system, in which at least one of the procedures in summarization module is performed manually by the user. Many contemporary ATSS can switch from fully automatic to semi-automatic mode. Essence Application produced by Document Management Partners (Belgium) (see "Softprom News") provides the user with an opportunity to set summary size and modify the dictionary. The user can set summary size in MS Word's AutoSummarize (see Gore 1997). Symmetric summarization can be realized in different modes. ATSS based on symmetric summarization methodology can process primary sources at entity-level as well as surface level; they can work in generic as well as in user focused mode; they can be fully or semi-automatic. PhiN 34/2005: 52 3 The methodology of symmetric summarizationSymmetric summarization is an interpretation of surface-level extraction, domain specific methodologies. In the process of symmetric summarization the computer program calculates functional weight for each sentence; sentences with the highest functional weights are selected and included in the summary. A functional weight of the sentence is the number of its connections with the rest of the sentences in a given text. Connections between sentences are identified by repetition of words from domain dictionary. The specific feature of symmetric summarization is that of symmetric relationship: if a sentence Z has N connections with a sentence Y, then sentence Y has N connections with sentence Z. Consider the following extract from Murray's paper entitled Changing technologies, changing literacy communities? (2000).
The solid underline indicates repeated words belonging to the domain indicated by the key word literacy in the title of the primary source. These words should be taken into account during summarization. Considering symmetric relationships the word writing in the first sentence is repeated in the second sentence; sentence (1) has one connection with sentence (2) through the repetition of the word writing; sentence (2) also has one connection with sentence (1) through the repetition of the same word. Writing is also twice repeated in the fourth sentence: first as writing and then as written. Consequently sentence (1) has 2 connections with sentence (4) through the repetition of writing. On the other hand (4) also has 2 connections with (1) through the repetition of the same word. Note that the following words are regarded identical according to the stemming principle: writing = written, syllabary = syllables, Phoenician = Phoenicians. Following the principle of symmetry the number of connections for each sentence is provided in Table 1. Sentence (4) has the highest number of connections and thus the highest functional weight, sentence (3) – the lowest. Accordingly sentence (3) would not be selected during summarization. This methodology of symmetric summarization has the following advantages.
PhiN 34/2005: 53
PhiN 34/2005: 54 In Computational Linguistics Laboratory at Katanov State University of Khakasia have been developed fully automatic (FASS) and semi-automatic (PASS) symmetric summarization systems. FASS employs surface-level and entity level methods to summarizes scientific HTML texts (see Stupin 2004); PASS is a user-focused, domain specific, surface level system that can be successfully used in foreign language teaching. 4 PASS – a semi-automatic symmetric summarization system4.1 The ideaThe general idea underlining PASS is the following. To summarize a scientific or a newspaper text a student is given two assignments.
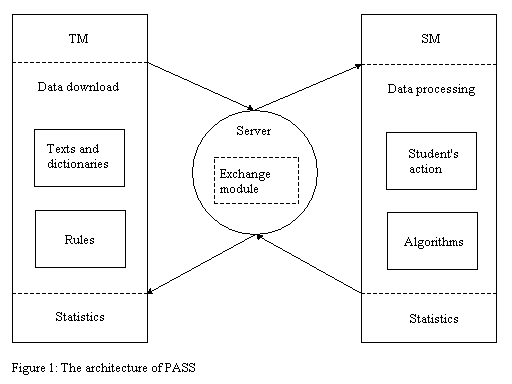
Basing on the dictionary provided by the student PASS will produce a summary. It was noticed (see Mani 2001) that summaries produced by surface level summarization systems are often not coherent because they consist of sentences that may have manifestations of connections with other sentences that were not selected during summarization. The student will use a number of transformation procedures to make a coherent summary, thus memorizing better syntactic structures and means providing speech coherence. While doing the assignments the student will be provided with statistical data about his mistakes. 4.2 The architecture of PASSPASS, realized in Delphi 7.0, can process .txt format files. It is a distributed system that has a teacher's module (TM) and a student's module (SM), both modules being linked via the exchange module on the specialized server. PhiN 34/2005: 55
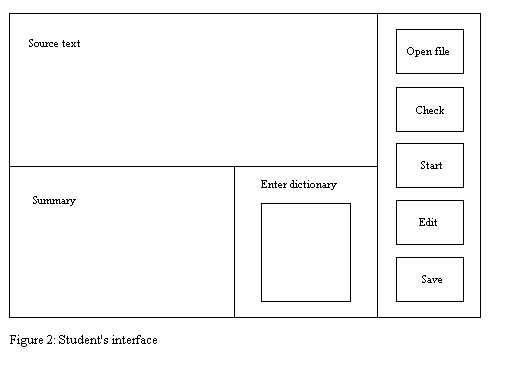
TM provides the teacher with an interface to access the server so as to 1) download texts to be summarized together with reference domain dictionaries, which will be matched with dictionary terms entered by the student; 2) specify rules determining the order of appearance of sentences selected from the primary source; 3) get access to statistics about students mistakes. SM module provides the student with an interface to do summarization assignments The functioning of SM involves the following procedures and algorithms.
4.3 Manual transformation proceduresHaving obtained the summary the student is required to edit it using manual transformation procedures so as to make the summary more coherent. These procedures are similar to those distinguished within the scope of generative and transformational grammars (see Van Valin 2001: 176–179) and include deletion, insertion, and modification of syntactic structure. Anaphoric and cataphoric components that manifest connections with the sentences that were not extracted from the primary source are deleted. Parenthetical words and phrases that signal logical relations between sentences are inserted. Sentences, whose syntactic structure doesn't conform to the summary style, are modified. For example after applying these procedures the sentence from the original text
PhiN 34/2005: 57 becomes
Application of such procedures requires a good command of the target language and works well for foreign language study.
4.4 EvaluationSince PASS involves knowledge of structural semantics and means of text coherence we decided to integrate it into Linguistic Text Theory course, a compulsory course studied by the students at the English Department of Katanov State University of Khakasia. 40 students worked with PASS at two classes, each class lasted 1 hour 20 minutes. At each class the students summarized 3 scientific texts, which dealt with the problems of text grammar, and for each text they were required to make up a domain dictionary consisting of 8 terms. I.e. the total number of speciality terms used by each student was 48. In 3 months after completion of the course the students were tested to determine the number of retaining terms. The test included the following types of assignments: translation from Russian into English, filling in blanks with suitable words, paraphrasing sentences using synonyms of highlighted words. The results were encouraging: more than half of the students (67 %) remembered all the terms, 22 % of students remembered 87 % of the terms, 8 % remembered 65 % of the terms, and 3 % remembered 48 % of the terms. PhiN 34/2005: 58 Next year we plan to integrate PASS into a course for undergraduate students so that it would be possible to test them 3 times: first in 3 months after course completion, then in 6 months and in 12 months after it. Such testing will give more reliable results. 5 ConclusionsIn this paper we described characteristics of semi-automatic text summarization systems and demonstrated how they can be applied in foreign language teaching. We can distinguish the following differences between ATSS and SATSS. 1) SATSS work on the dictionary compiled by the user. In this respect they are similar to user-focused ATSS and differ from generic ATSS. 2). SATSS are domain specific, surface level systems. While in computer science incoherence of summaries produced by surface level systems is considered to be their major drawback, in FLT it may be an advantage since it provides the teacher with additional opportunities to introduce to learners means of text coherence. The development of semi-automatic text summarization systems can be regarded as a subfield of applied linguistics. ReferencesThe Center for Intelligent Information Retrieval (2000), available at: [http://ciir.cs.umass.edu/] Gore, Karenna (1997): What less can we say? Computers have the answer, available at: [http://slate.msn.com/id/2419] Iatsko, Viatscheslav A.: "Symmetric summarization: main principles and methodology", in: Nauchno-technocheskaya informatsia. Ser. 2, No. 5, 18–28. [In Russian] Kan, Min-Yen, McKeown, Kathleen R. (1999): Information extraction and summarization: domain independence through focus types. Columbia University. New York. Mani, Inderjeet, Maybury, Mark T. (1999): "Introduction", in: Advances in Automatic Text Summarization, IX–XV. Mani, Inderjeet (2001): Summarization Evaluation: An Overview. The MITRE Corporation. Reston. PhiN 34/2005: 59 Murray, Denise E. (2000): "Changing technologies, changing literacy communities?", in: Language learning and technology. Vol. 4, No. 2, 43–58, available at: [http://llt.msu.edu/vol4num2/murray/default.html] Paice, Chris D. (1990): "Another stemmer", in: SIGIR Forum 24/3, 56–61. Softprom News, available at: [http://www.softprom.com/developers_news.phtml?developer_id=3] [In Russian] Strzalkowski, Tomek, Stein, Gees C., Wang, Jin and Wise, Bowden (1999): "A robust practical text summarizer", in: Advances in Automatic Text Summarization, 137–154. Stupin, V. S. (2004): "Automatic summarization by the method of symmetric summarization", in: Computational Linguistics and Intellectual Technologies. 579–591. [In Russian] Van Valin, Robert D. Jr. (2001): An introduction to syntax. Cambridge. Cambridge University Press. Veize, A. A. (1985): Reading, summarizing, and abstracting foreign texts. Vysshaya Shkola. Moscow. [In Russian] Zamora, Antonio (2004): Modifications to the Paice/Husk Stemmer, available at: [http://www.scientificpsychic.com/paice/paice.html] |