|
Das Spektrum reicht von sehr textnahen Übersetzungen bis hin zu sehr freien Übertragungen, es umfasst u.a. eine antikisierende Übersetzung von Karl Lachmann und eine Dialektübertragung ins Berlinerische von Ingeborg Vetter (A): |
| Ick denke oft, ick habe allet satt |
| Und von der janzen Welt die Schnauze voll, |
| Wo Ausjebufftheit jilt als Ruhmesblatt; |
| Man weeß nich, wie man so schnell kotzen soll! |
| Denn biste brav und ehrlich, jehste unter; |
| Vertrauste, wirste huckepack jenommen; |
| Uff deine Kosten leb’n die Strolche munter, |
| Du bist derweilen uff’en Hund jekommen. |
| Nullbock is schick und Fleiß is unanständig, |
| Verbrechen logo und Jewalt zu achten, |
| Jeschmier uff Tisch und Wänden, narrenhändig, |
| Sowie Jejaul mußt du als Kunst betrachten. |
| Wärst du nich hier, hätt ick dir nich so jern, |
| Verfügte ick mir uff’en andern Stern! (vgl. Erckenbrecht 2001:258) |
|
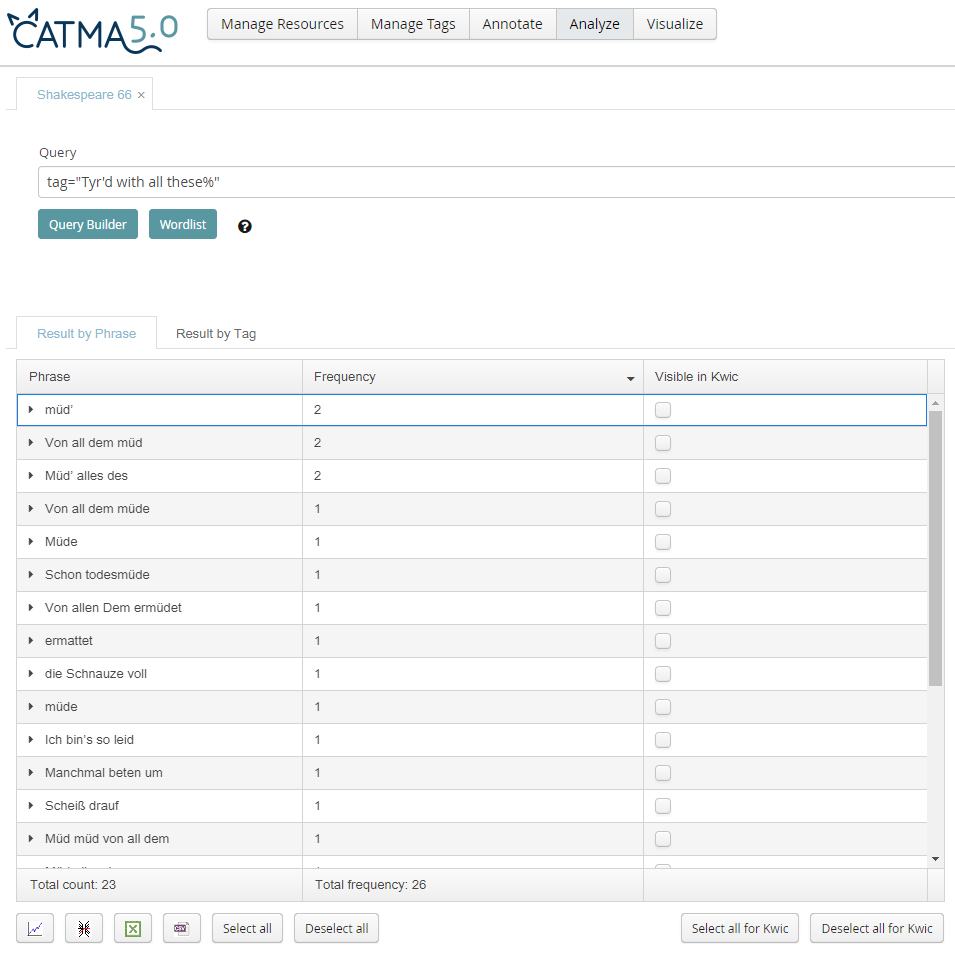
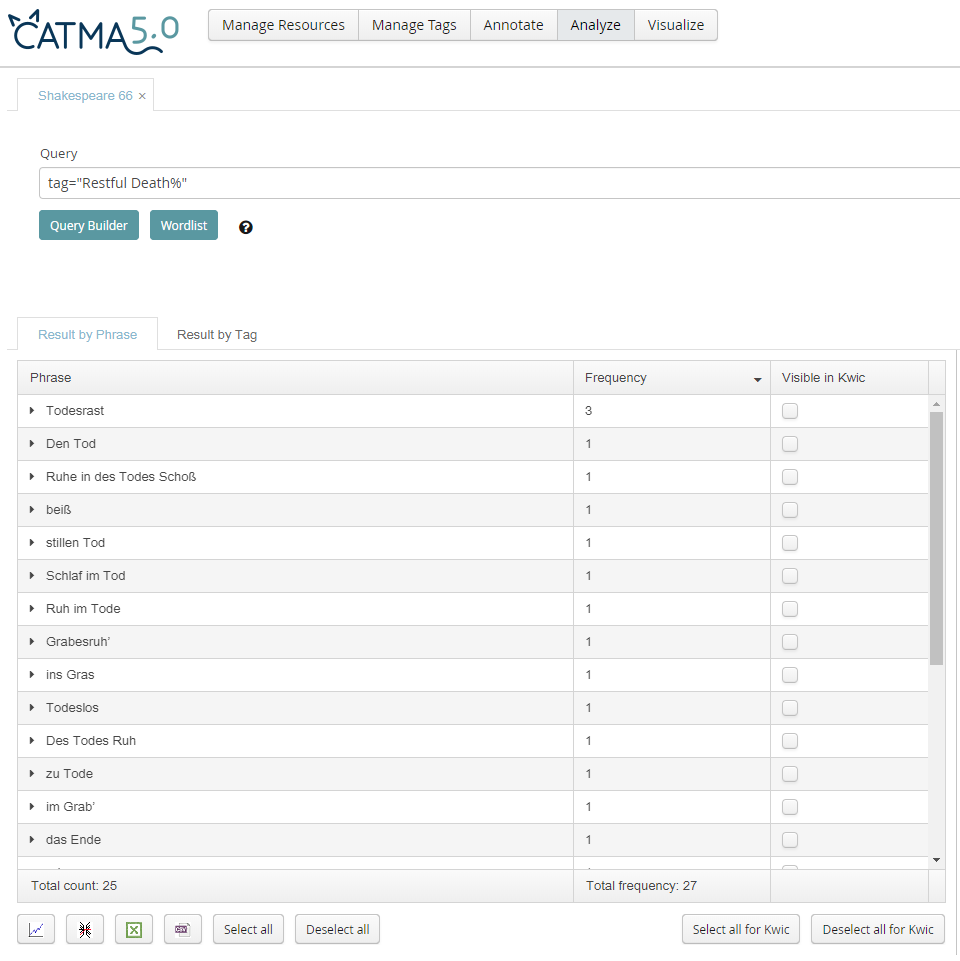
Zur digitalen Analyse verwendeten wir ein Verfahren, das im Rahmen des DFG-Projektes forTEXT an der Universität Hamburg unter Federführung von Jan-Christoph Meister entwickelt wurde: Das Programm CATMA (Meister, Petris, Gius et al. 2018) soll eine digitale Forschungsumgebung für Texterschließung, Textannotation und -analyse bieten, die durch die einfache Kombination verschiedener digitaler Methoden unterstützt wird.2 CATMAs Annotationsfunktion ist für unser Vorhaben produktiv, da es Annotationen sowohl wort- als auch kontextbezogen vorzunehmen erlaubt. Nicht nur einzelne Wörter, sondern Satzteile bzw. Verse können so im Sinne des von Wendell Piez identifizierten "hermeneutic markup" (Piez 2010) annotiert werden. Unsere Frage nach (in)stabilen Übersetzungen bewegt sich zum einen auf der Wortebene, zum anderen auf Versebene: Der idiomatisch gefasste Vers 12 "And captive good attending captain ill" erschien uns besonders interessant für Übersetzungsvariationen. Die ausgewählten 26 Übersetzungen wurden mithilfe des Standard-Textverarbeitungsprogramms Microsoft Word digitalisiert und in den cloud-basierten Speicher von CATMA geladen. Hier ergaben sich Anwendungsschwierigkeiten, da die Dokumente bei Tippfehlern nicht in der Umgebung CATMAs, sondern nur im Quelldokument angepasst werden können. Somit musste bei einem Änderungsbedarf der gesamte Upload-Prozess wiederholt werden. Zudem erfordert CATMA, das Annotationsvorhaben auf mehreren Ebenen durchzuführen. Für Anwender*innen ohne Informatikhintergrund erscheint dies wenig intuitiv: Zuerst war manuell ein Speicherort für das Korpus "Shakespeare 66" zu benennen. Per Drag and Drop konnten die relevanten Übersetzungen daraufhin dem Korpus zugeordnet werden. Hiervon ausgehend wurde eine "Tag Library" namens "Übersetzungen" erstellt. Diese Tag Library lässt sich in einem weiteren Schritt noch feiner ausdifferenzieren: Kleinere Themen können in Form von "Tagsets" gruppiert werden. Für das vorliegende Projekt wurde aus Gründen der einfachen Handhabbarkeit lediglich ein Tagset gewählt, nämlich "Motive".3 In diesem Tagset wurden nun die jeweiligen Annotationen (= "Tags") festgelegt. PhiN 88/2019: 38 Uns interessierte, wie "Tired with all these" (v.1), "restful death" (v.1), "purest faith" (v.4), "art" (v.9), "And captive good attending captain ill" (v.12) sowie "my love” (v.14) übersetzt wurden. Unsere Hypothese war, dass "art" stabil mit der wörtlichen Entsprechung "Kunst", "my love" mit "meine Liebe" und "purest faith" mit "reinste Treue" übersetzt wurden, die anderen Beispiele hingegen weniger eindeutige Übersetzungsergebnisse erzielen würden. Je größer die Wortfolge, desto mehr Varianz erwarteten wir bei der Übersetzung. Dementsprechend wurden die Tags erstellt und einer Farbe zugeordnet. In der Anwendung war Folgendes zu beachten: Wie bei den Annotationen schon auf mehreren Ebenen gedacht werden musste, um für das Programm die verschiedenen Verknüpfungen untereinander abzubilden, ist es auch für die Annotationspraxis wichtig, neben der Annotation zusätzlich einen Speicherort zu benennen, in dem die Anwendung des Tagsets für eine Quelle gesichert wird. Bevor die Annotation beginnen kann, sind also zwei Arbeitsschritte vonnöten: Nachdem das Tagset "Motive" in das geöffnete Dokument geladen worden ist, muss eine "Annotation Collection", also ein neuer Speicherort manuell generiert werden.4 Sind derart die formalen Bedingungen geschaffen, kann nun annotiert werden: Die zu annotierende Textsequenz wird markiert und per Klick mit der dem Tag zugeordneten Farbe unterlegt. Ab diesem Punkt setzte die ‚klassische‘ literaturwissenschaftliche Arbeit ein: Die Entscheidung, welche Textsequenz annotiert wird, folgte den Arbeitsroutinen des geisteswissenschaftlich geschulten Lesens – der kritischen und reflektierten Sicht auf das Textkorpus und das Original. Generell versuchten wir, möglichst nah am Original zu annotieren: Alle einzelnen Wörter wurden nur als solche annotiert, alle Versübersetzungen dementsprechend markiert und Komposita in ihrer jeweiligen Zusammensetzung berücksichtigt.5 Nach Beendigung der Annotation konnten die jeweiligen Tags in einer Tabelle dargestellt werden, die einen Überblick über alle Übersetzungen erlaubte. Dabei wurde die Häufigkeit einer Übersetzung angegeben. Diese Tabelle kann als Excel- oder bereinigte CSV-Datei ausgegeben werden.6 Was das Programm nicht leistet, ist eine chronologische Auflistung der Gedichte, die für unsere Forschungsfrage relevant wäre. Im Dokumenttitel wurde von uns allerdings das Erscheinungsjahr festgehalten, so dass wir über eine händische Analyse die Übersetzungen chronologisch ordnen konnten. Kritisch kann angemerkt werden, dass auch Excel als Datenverarbeitungsprogramm solche Funktionen anbietet. CATMAs Stärke ist allerdings, dass durch die cloudbasierte Speicherung mehrere Nutzer*innen ortsunabhängig das Material untersuchen könnten. PhiN 88/2019: 39 3 Einzelergebnisse"Tired with all these" (v.1) – das Leiden an der Welt, mit dem das Sonett beginnt, ist teilweise wörtlich transponiert worden: "Müd von all(‘) dem" bildet sowohl die englische Semantik als auch die Wortstellung nach, während "Von all dem müd" im Deutschen geläufiger erscheint. Beide Varianten treten jeweils sechsmal auf. In vier Versionen wird der Überdruss lediglich durch das Adjektiv "müde" ausgedrückt. 1990 weitet Biermann die Semantik durch Verdopplung ("müd müd von all dem"), auch Steigerungen wie "todesmüde" (Benjamin, 1930), "ermattet" (Jordan, 1861) und "Das quält" (Baltzer, 1910) treten auf. Mehr Vehemenz und Aggression drücken die freieren Übertragungen aus: "Scheiß drauf" (Amme B, 2000), "Hab’s herzlich satt" (Heubner, 1856) und "Ich bin’s so leid", wie Keil (1980) formuliert. Vetter (A, 2000) drückt gleich zweimal Weltekel aus: "Ick denke oft, ick habe allet satt / Und von der janzen Welt die Schnauze voll". |
PhiN 88/2019: 40
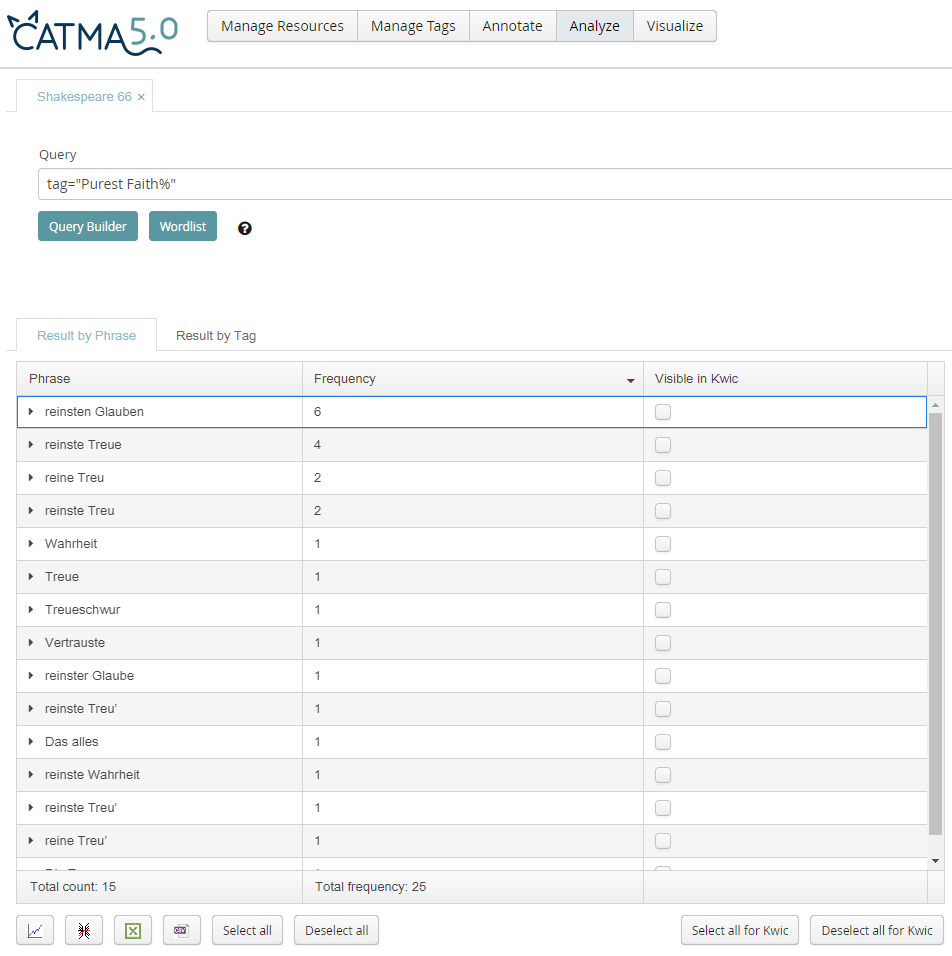
Abb. 3: Einzelergebnisse zu "Purest Faith" Während "purest" stabil mit "rein" oder dessen Superlativ "reinste(r/n)" übersetzt wird, besitzt faith zwei Hauptbedeutungen, nämlich "Treue" und "Glauben". In unserer Stichprobe zeigt sich eine starke Präferenz für "Treu‘" und "Treue" (13 Ausprägungen), während "Glaube(n)" siebenmal vertreten ist. Die sexuelle Konnotation von "purest faith" wird in diesen Übertragungen nicht recht deutlich. Gänzlich anders lösen Mauntz sowie Claus und Csollány das Problem, indem sie "faith" mit "Wahrheit" übersetzen und somit eine Bedeutungsverschiebung in Richtung einer juristischen Semantik vornehmen. PhiN 88/2019: 42 |
|
Abb. 4: Einzelergebnisse zu Vers 12
|
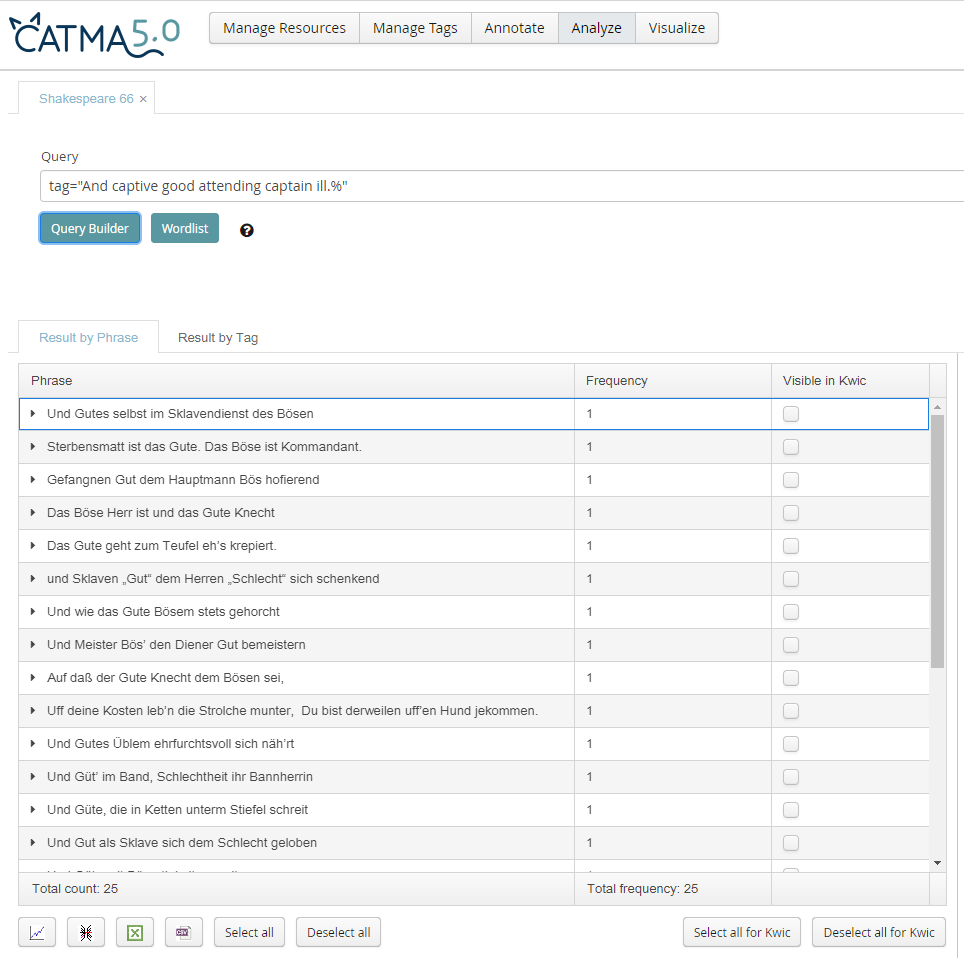
Vers 12 ("And captive good attending captain ill") ist semantisch und grammatisch besonders anspruchsvoll, weil die englischen Wörter captive und captain sowohl Adjektive als auch Nomen sind: Captive meint so viel wie "gefangen" und "Gefangener", captain sowohl "hauptsächlich" als auch "Hauptmann" im Sinne eines militärischen Rangs. Zu dem Kontrast von Hauptmann und Gefangenem tritt in Shakespeares Ausgangstext ein weiterer, damit verbundener Kontrast hinzu: good und ill, die ebenso als Adjektive oder Nomen gelesen werden können. Das Verb attending wiederum kann "horchen"/ "gehorchen", aber auch "dienen" bedeuten. Shakespeare akzentuiert das militärische Moment der Unterwerfung negativ (captain ill), während das Moment der Gefangenschaft positiv konnotiert wird (captive good). PhiN 88/2019: 43 In unserer Stichprobe wird der Kontrast von good und ill stabil mit Variationen des Guten und Bösen bzw. Schlechten übersetzt. Diese Semantik wird sowohl adjektivisch als auch nominal ausgedrückt, häufig tritt das Gute/Böse als Personifizierung auf. Hiermit verbindet sich das semantische Feld des Militärischen, und zwar in Wendungen wie "Hauptmann Bös" (Heubner), "Häuptling Schlecht" (Jantzen) und "Hauptmann Schlecht" (Kranz) sowie "das Böse ist Kommandant" (Claus & Csollány). Antikisierend verwendet Lachmann den Neologismus "Bannherrin", der die rechtliche Bedeutung eines Gebotes oder Verbotes ("Bann") einbringt: "Und Gütʼ im Band, Schlechtheit ihr Bannherrin". Weitaus häufiger jedoch wird ein anderes semantisches Feld bemüht, nämlich der Topos von Herrschaft und Knechtschaft. Dieser wird als "Herr und Knecht" bzw. "Herr und Sklave" realisiert und muss frei nach Karl Marx als Verhältnis einer unfreiwilligen Ausbeutung (und nicht etwa als Schutzverhältnis) verstanden werden. Drastisch formuliert Biermann 1990: "Und Güte, die in Ketten unterm Stiefel schreit". Weitaus freier heißt es bei Vetter (A) "Uff deine Kosten leb’n die Strolche munter,/Du bist derweilen uff’en Hund jekommen." In unserer Stichprobe taucht diese Bedeutungsverlagerung erstmals 1894 bei Mauntz auf und wird dann im gesamten 20. Jahrhundert wiederholt aufgegriffen. Als Korrelat hierzu erscheinen die vielen Ausdrücke des Dienens bzw. des Dienstes, beispielsweise "und Häftling Gut im Dienst beim Häuptling Schlecht" bei Jantzen (Hervorh. i. O.). |
|
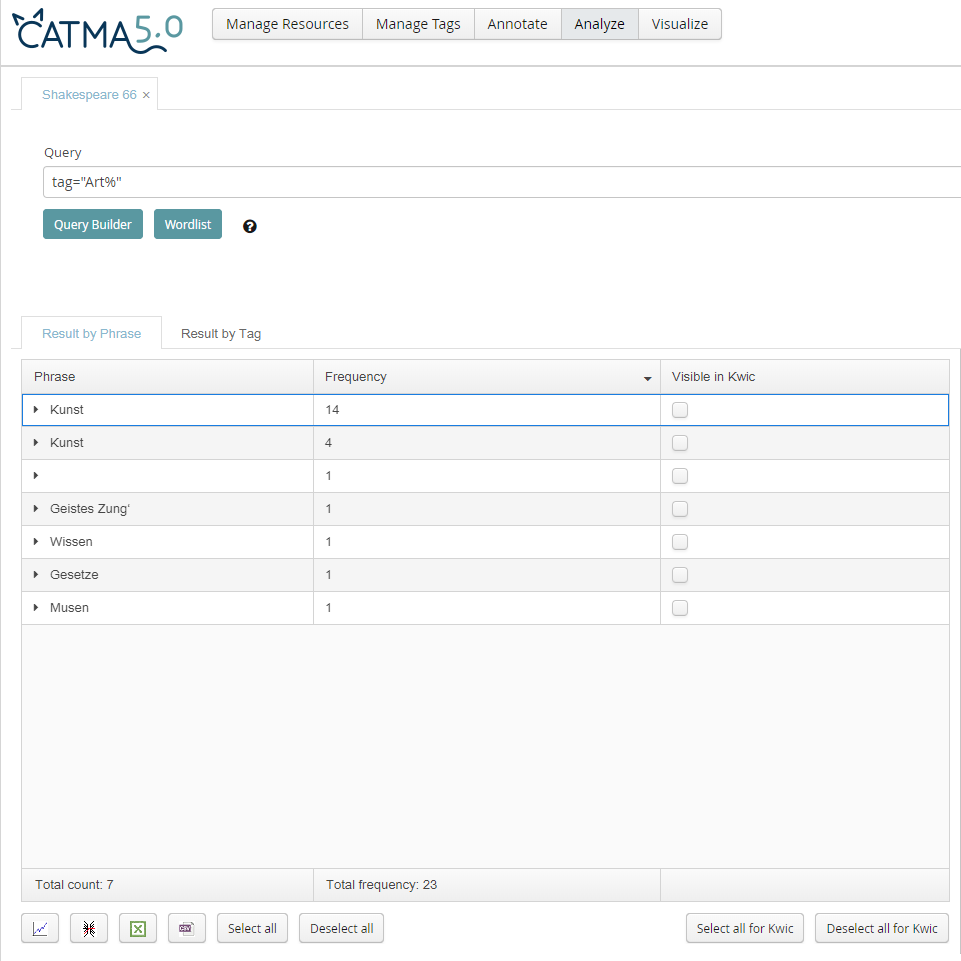
Abb. 5: Einzelergebnisse zu "Art"
|
PhiN 88/2019: 44 Wie erwartet wurde "art" stabil mit dem Kollektivsingular "Kunst" (in 18 Texten) übersetzt. Zu Shakespeares Zeit allerdings schloss die Semantik von art sowohl die Künste als auch die Wissenschaften ein (dies analog zur Wortbedeutung von lat. ars). Diese frühneuzeitliche Bedeutung zeigt sich in den Übertragungen "Wissen" (Schücking und Robinson), "Musen" (Heubner) und "Geistes Zung‘" (Jantzen). Vor diesem Hintergrund ist die Übertragung "Gesetze" (Claus und Csollány) nicht juristisch, sondern genieästhetisch im Sinne geregelter Kunst zu verstehen.
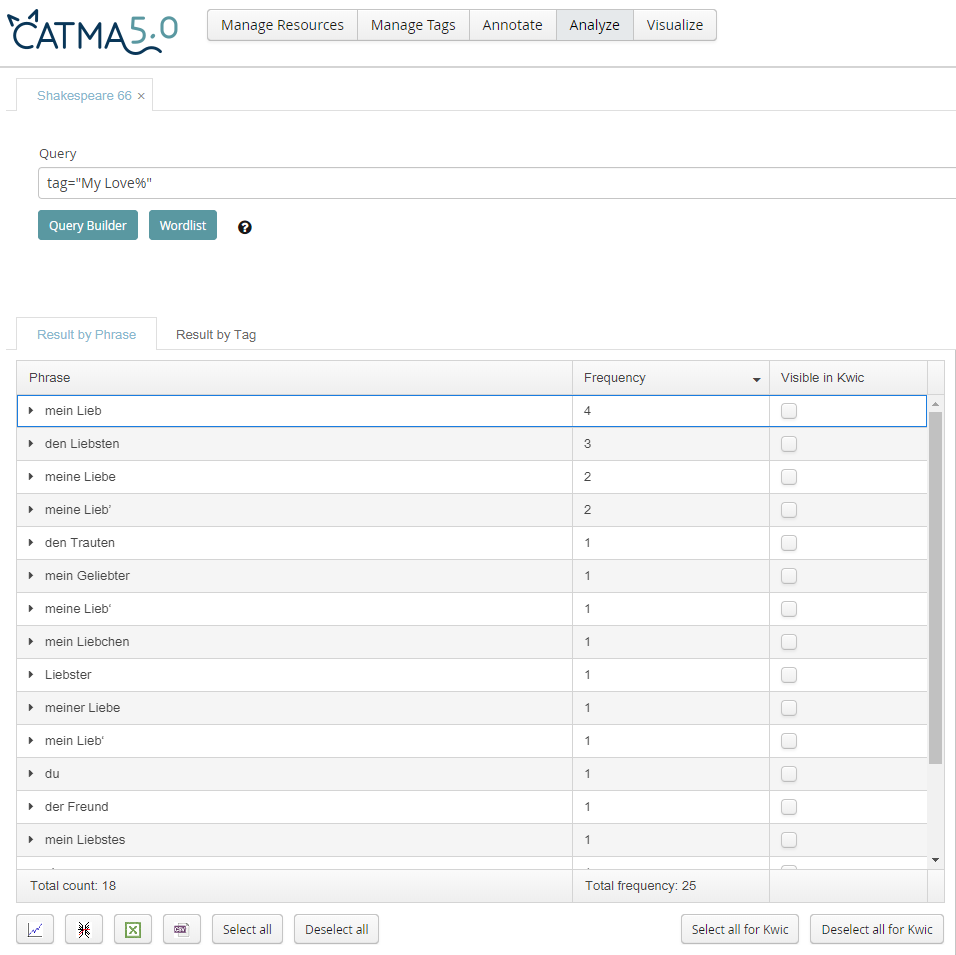
PhiN 88/2019: 45 In den 26 Texten wird "my love" achtmal geschlechtsneutral durch die wörtliche Übersetzungen "meine Liebe"/ "mein Lieb‘" übertragen. Der Superlativ "mein Liebstes" taucht ebenso auf wie dessen Abwandlung "Liebster". In dieses männliche Feld mit insgesamt sieben Nennungen von Personenbezeichnung fallen auch die Wörter "Geliebter" (Lachmann), "Trauter" (Tschischwitz) und "Freund" (Schücking und Robinson). Lediglich zwei Texte sprechen ein weibliches Gegenüber an: "sie" (Claus und Csollány) und "mein Liebchen" (Biermann), das im strikten grammatischen Sinn zwar geschlechtsneutral gelesen werden kann, seit Johann Wolfgang von Goethe und Heinrich Heine aber weiblich konnotiert ist. Fazit"Die Semantik stellt für die digitale Literaturanalyse nach wie vor eine der größten Herausforderungen dar" (Weitin, Herget 2017: 30). Was Thomas Weitin und Katharina Herget im Blick auf Topic Modeling konstatieren, können wir mit Blick auf ein digitales Annotationsverfahren bestätigen. Wir haben dieses Verfahren an einem kleineren Korpus von Übertragungen des 66. Sonetts von William Shakespeare erprobt. Dieses Korpus ließ sich sowohl durch die individuelle Lektüre als auch durch unsere mit dem Programm CATMA definierten Annotationen analysieren. Unser Ziel war es, zu untersuchen, wie ausgewählte Wörter, Wortfolgen und Verse übersetzt wurden, ob die Übersetzungen sich ähneln oder nicht und ob der Zeitfaktor eine Rolle spielt – sind gewisse Übersetzungsmoden auszumachen? Um diese Fragen zu beantworten, haben wir die betreffenden Übersetzungen annotiert, d.h. durch Tags digital markiert. Dabei waren wir interpretativ tätig, indem wir entschieden, welches Wort, welche Wortfolge bzw. welcher Vers im Deutschen dem englischen Ausgangstext entspricht. Mithilfe des Programms konnten wir die Annotationen miteinander vergleichen und uns die textuelle Umgebung vor und hinter der Annotation anzeigen lassen. Letzteres ließ sich visualisieren, war aber für unsere Fragestellung unerheblich. Darüber hinaus war es möglich, das Programm die Häufigkeit der Annotationen zählen zu lassen. Diese Zählung haben wir in eine Excel-Tabelle exportieren können. Die so gewonnen Daten bildeten die Basis für unsere Interpretation. Keine Ergebnisse konnten wir zu der historischen Fragestellung gewinnen, da es nicht möglich war, in CATMA Chronologien darzustellen. Dies würde bei größeren Textkorpora noch nachteiliger sein als bei unserem Textkorpus. Darüber hinaus erwies sich die Größe unserer Stichprobe als zu klein, um historische Übersetzungsmoden auszumachen. Unsere Thesen zu stabilen bzw. variantenreichen Übersetzungen hingegen haben sich teilweise bestätigt. So wurde "art" wie erwartet überwiegend mit "Kunst" übersetzt. Überraschenderweise spielte aber auch die Etymologie des Wortes eine Rolle, da lat. ars nicht nur "Kunst", sondern auch "Wissenschaft" meint und "art" dementsprechend übertragen wurde. PhiN 88/2019: 46 Insgesamt war es möglich, anhand der gewonnenen Daten eine semantische Analyse durchzuführen. Dies gelang am besten am Beispiel eines ganzen Verses, wobei der ausgewählte Vers 12 "And captive good attending captain ill" besonders schwer zu übertragen ist und daher viele unterschiedliche Übersetzungen provoziert hat. Trotzdem ließen sich zwei dominante Muster ausmachen, nämlich die die semantischen Felder "Hauptmann/Gefangener" und "Herr/Knecht". Traten in unserer Stichprobe sehr ungewöhnliche Übersetzungen wie "Wahrheit" für "purest faith" auf, so ließen sich diese nur im Blick auf das ganze Sonett deuten. Dabei war es umständlich, die Darstellungsebenen zu wechseln, so dass ein direkter Vergleich zwischen Gedicht und Annotation nicht möglich war. Somit oblag es uns, die Gedichte für die Analyse mental bzw. analog parat zu haben. In diesem Kernbereich geisteswissenschaftlicher Arbeit am Text fiel uns auf, dass etliche Übersetzungen unserer Stichprobe sich an der äußerst wortgetreuen Erstübersetzung von Johann Joachim Eschenburg aus dem Jahr 1787 orientieren – ein Ergebnis, das nicht digital, sondern durch die traditionelle literaturwissenschaftliche Analyse zustande kam. In diesem Kontext sei eine generelle Eigenschaft von digitalen Literaturverarbeitungswerkzeugen angesprochen: Sie erfordern einen anderen Blick auf Texte als denjenigen, der in der Praxis literaturwissenschaftlichen Arbeitens eingeübt wird. Mithin schafft die Technik Probleme, solche nämlich des einfachen Verständnisses und der Anwendung: CATMA ist nicht ohne weiteres intuitiv zu benutzen, sondern erfordert eine nicht zu verachtende Einarbeitungszeit – was u.a. daran liegt, dass "die Adaption von Werkzeugen zur Verarbeitung natürlicher Sprache an die doch sehr anderen Verhältnisse literarischer Sprache" sehr aufwendig ist (Jannidis 2017:26). Diese digitalen Übersetzungsschwierigkeiten schlagen sich in Forschungsvorhaben wie dem unseren nieder. Damit die Digital Humanities ihren Status als "Hilfswissenschaft (im emphatischen Sinne einer guten Assistenz" (Krajewski 2019: 4) einnehmen können, bedarf es weiterer Projekte und einer größeren universitären Routine der Anwendung und Integration digitaler Analysemethoden. BibliographieErckenbrecht, Ulrich (ed.) (2001): Shakespeare Sechsundsechzig. Variationen über ein Sonett. 2. erweiterte Ausgabe. Kassel: Muriverlag. PhiN 88/2019: 47 Erken, Günther (2009): "Die deutschen Übersetzungen." In: Shakespeare-Handbuch. Die Zeit – Der Mensch – Das Werk – Die Nachwelt. Ed. Ina Schabert. Stuttgart: Alfred Kröner. Fertig, Eymar (1999): "Nachtrag zur Bibliographie 'Shakespeares Sonette in deutschen Übersetzungen 1787-1994', erweitert durch szenische und musikalische Gestaltungen. Berichtszeit: 1784-1998". In: Archiv für das Studium der neueren Sprachen und Literaturen 151: 236 (1999), 265-324. Jannidis, Fotis (2017): "Perspektiven quantitativer Untersuchungen des Novellenschatzes". In: Zeitschrift für Literaturwissenschaft und Linguistik (2017) 47: 1, 7-27. Krajewski, Markus (2019): "Digital Humanities: Hilfe für die Hilfswissenschaft". In: FAZ.NET. https://www.faz.net/aktuell/feuilleton/hoch-schule/digital-humanities-hilfe-fuer-die-hilfswissenschaft-16131498.html (abgerufen am 16.05.2019). Leithner-Brauns, Annette (1995): "Shakespeares Sonette in deutschen Übersetzungen 1787-1994: Eine bibliographische Übersicht". In: Archiv für das Studium der neueren Sprachen und Literaturen 147: 232 (1995), 285-316.. Meister, Jan-Christoph; Petris, Marco; Gius, Evelyn et al. (2018): CATMA (Version v5.2). Zenodo. http://doi.org/10.5281/zenodo.1470119. Piez, Wendell (2010): "An architectural outline". King’s College, DH 2010, London. http://piez.org/wendell/papers/dh2010/index.html (abgerufen am 09.05.2019) Shakespeare, William (1995): The Sonnets and a Lover’s Complaint. Ed. John Kerrigan. London: Penguin Books. PhiN 88/2019: 48 Weitin, Thomas (ed.) (2017): Zeitschrift für Literaturwissenschaft und Linguistik 47: 1. https://doi.org/10.1007/s41244-017-0048-4. Weitin, Thomas (2017a): "Einleitung: Scalable Reading". In: Zeitschrift für Literaturwissenschaft und Linguistik (2017) 47: 1, 1-6. Weitin, Thomas und Katharina Herget (2017): "Über einige Probleme beim Topic Modeling literarischer Texte". In: Zeitschrift für Literaturwissenschaft und Linguistik (2017) 47: 1, 29-48.
Anmerkungen1 Beteiligt waren Friedrich Michael Dimpel, Bent Gebert, Katharina Herget, Fotis Jannidis, Katja Mellmann, Nicolas Pethes, Christin Schätzle und Thomas Weitin. 2 Wir danken Janina Jacke und Jan Horstmann aus dem forTEXT-Team herzlich für ihre persönliche Beratung und Unterstützung. 3 Da man nur einzelne Tagsets, nicht aber ganze Tag Libraries in den Bearbeitungsmodus der Dokumente laden kann, fiel die forschungsökonomische Entscheidung, die zu untersuchenden Tags nur in einem Tagset zu gruppieren. 4 Geschieht dies nicht, läuft man Gefahr, eine Quelle zwar annotieren, aber später nicht vergleichen zu können, da das Programm nicht weiß, aus welchem Speicherort es die annotierten Formen laden soll. Manchmal, aber für uns nicht erkennbar unter welchen Bedingungen und deshalb nicht verlässlich, werden auch automatische Annotation Collections erstellt. 5 Dabei stellte sich die Frage, ob auch Artikel zu annotieren sind; wir entschieden uns generell dagegen – außer in begründeten Ausnahmen, wenn z.B. "Restful Death" nur durch "der Tod" übersetzt worden war. 6 Die Auswertungstabellen der jeweiligen Tags können im Anhang eingesehen werden. 7 Shakespeares "art" wurde insgesamt 18 Mal mit "Kunst" übersetzt, unsere Tabelle zählt jedoch 14 plus vier. Diese Darstellung ergibt sich mutmaßlich aus dem Umstand, dass wir "Kunst" mit und ohne Leerzeichen annotiert haben, ohne dies zu bemerken. PhiN 88/2019: 49 Anhang: Tabellen der Worthäufigkeiten"Document Frequency" bezeichnet die Häufigkeit, mit der die genannte Phrase im Einzeltext, d.h. in der jeweiligen Übersetzung vorkommt – in der Regel ist dies genau einmal der Fall. "Total Frequency" bezeichnet die Häufigkeit der Phrase im Textkorpus. |
|
Tag "Tired with all these"
PhiN 88/2019: 50 Tag "Restful Death"
PhiN 88/2019: 51 Tag "Purest Faith"
PhiN 88/2019: 52 Tag "Art"7
PhiN 88/2019: 53 Tag "And Captive Good Attending Captain Ill”
PhiN 88/2019: 54 Tag "My Love"
|